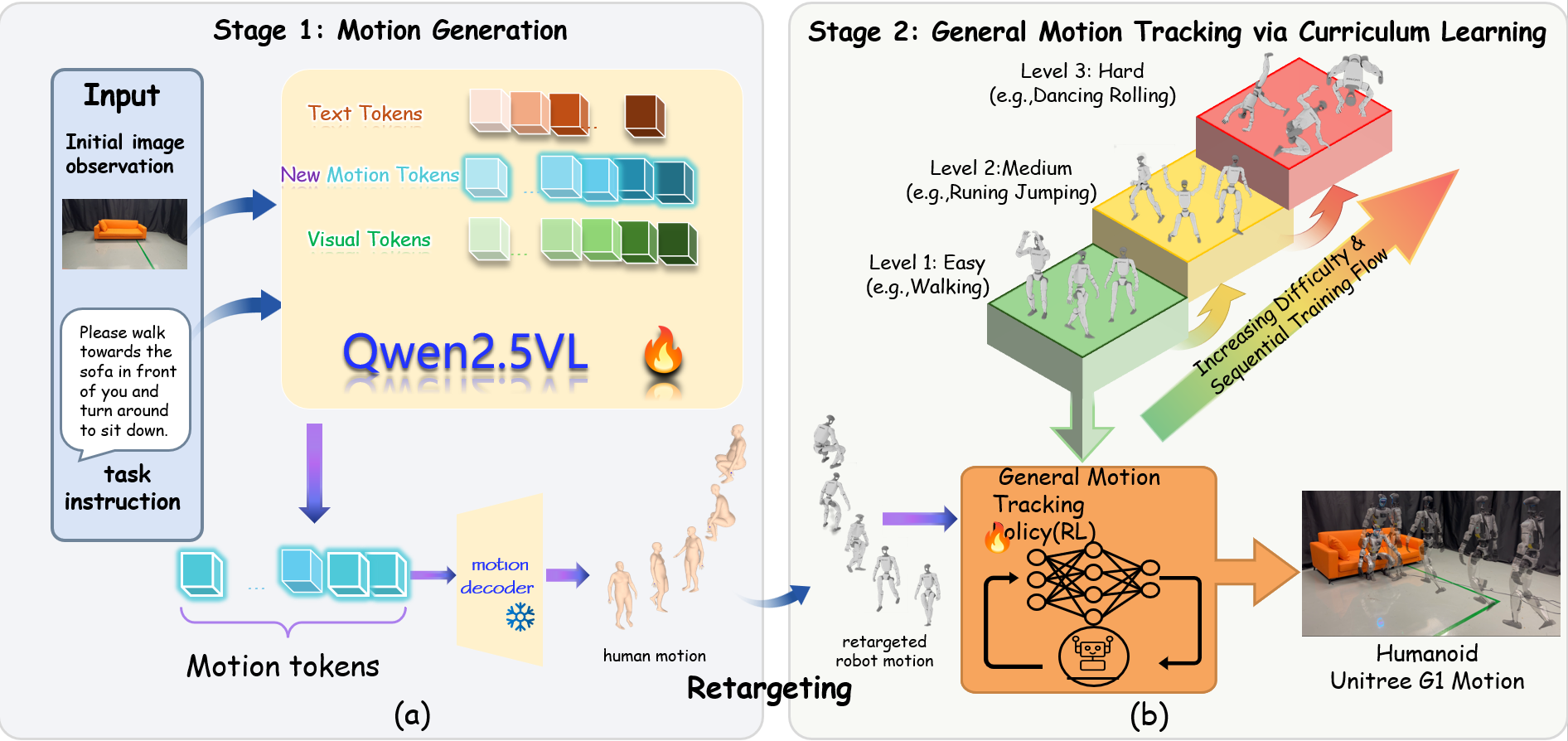
Overview
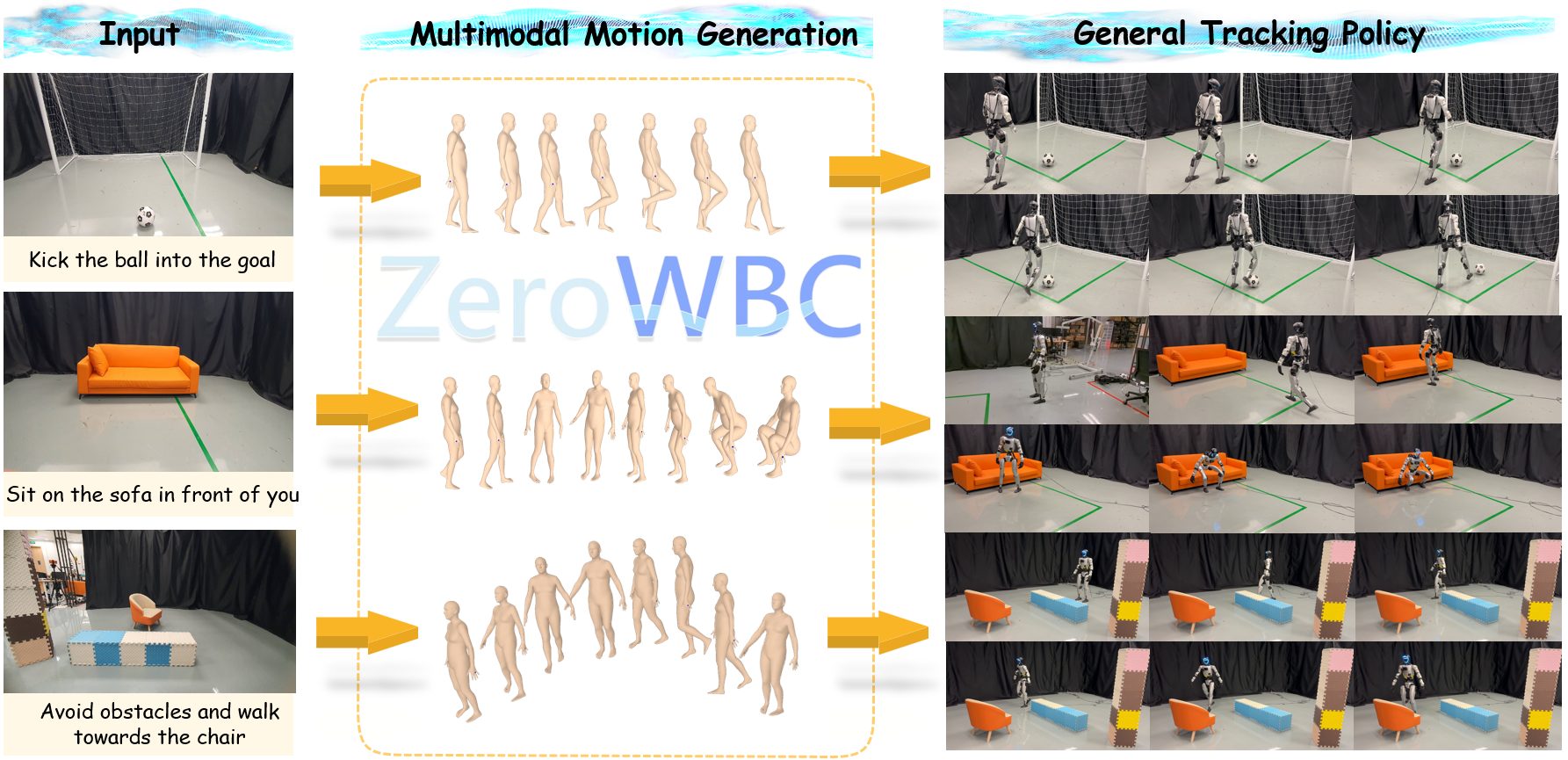
Overview of the ZeroWBC framework. We propose a novel framework that learns natural humanoid visuomotor control directly from human egocentric videos. The pipeline takes an initial egocentric image and text instruction as input (Left), synthesizes human whole-body motions via a fine-tuned vision-language model (Middle), and executes robot motion on the Unitree G1 robot using a robust general tracking policy (Right). ZeroWBC enables complex scene interactions like kicking, sitting, and obstacle avoidance with zero real robot teleoperation data.