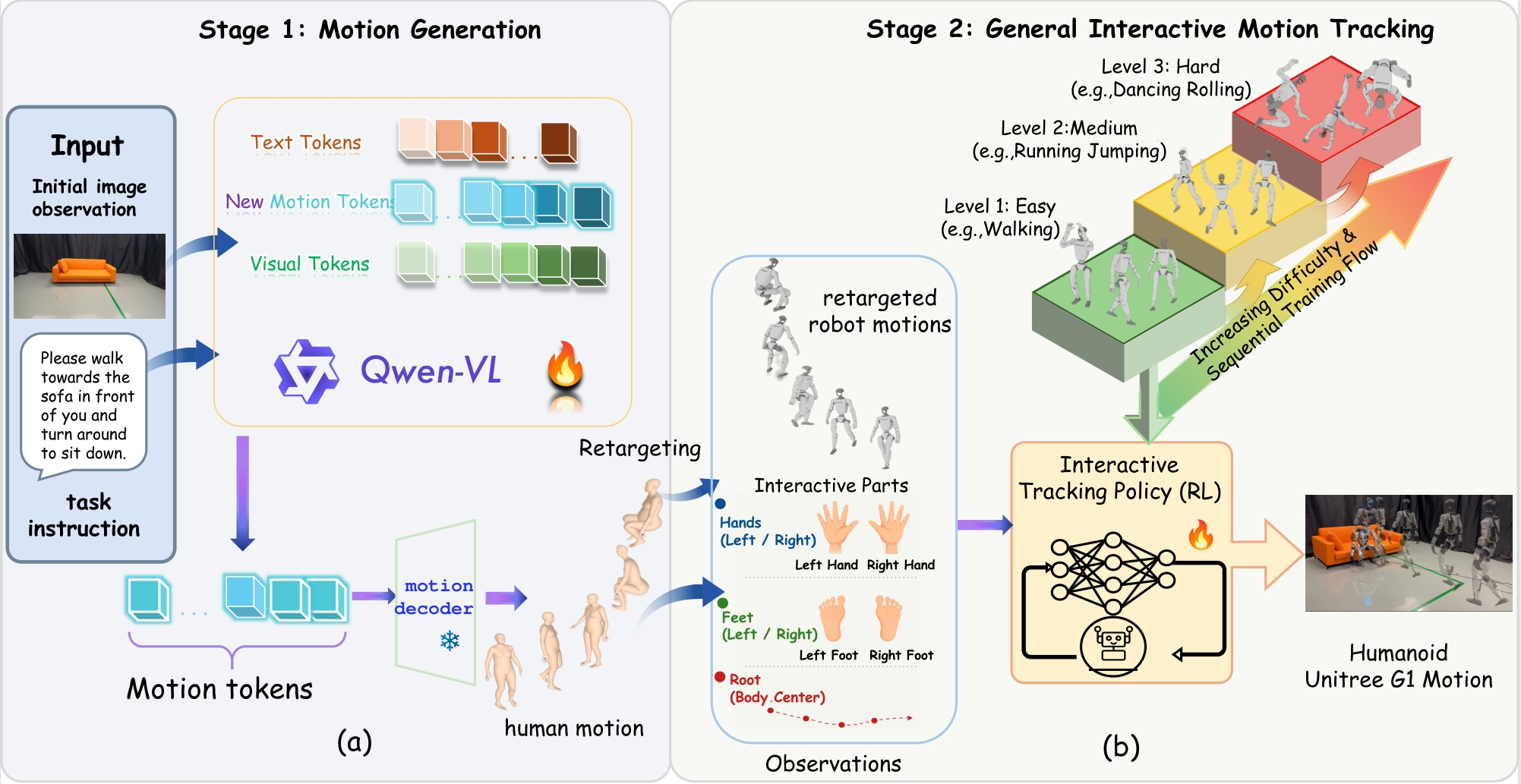
Overview

Overview of the ZeroWBC framework. The pipeline takes an initial egocentric image and text instruction as input (Left), synthesizes human whole-body motions via a fine-tuned vision-language model (Middle), and executes robot actions on the Unitree G1 robot using a general interactive tracking policy (Right).